Synthetic Data for Public Policy Research Unlocking Key Benefits
Acutus Ai
February 16, 2026
Reading Time: 5 Min

Explore how synthetic data enhances public policy research by ensuring privacy, improving accuracy, and cutting costs. Learn about its key benefits for testing policies, modeling scenarios, and providing faster insights.
In the world of public policy research, synthetic data is proving to be a game-changer. By tackling challenges related to privacy, accuracy, and efficiency, it offers significant improvements over traditional research methods. This innovative approach enables researchers to gain valuable insights while protecting sensitive information, streamlining the process, and reducing costs. Here’s why synthetic data is reshaping the way we conduct policy research:
1. Privacy Protection and Regulatory Compliance
One of the standout benefits of synthetic data is its ability to safeguard privacy and ensure compliance with key regulations. Unlike traditional methods that rely on anonymizing real personal data, synthetic data creates entirely new records that do not link to actual individuals. This eliminates privacy risks and simplifies compliance with privacy laws such as HIPAA, FERPA, and the CCPA.
Eliminating Privacy Risks
Synthetic data removes the risk of privacy breaches by simulating data based on real-world statistical models rather than actual personal information. Researchers can study sensitive topics like healthcare access, voting trends, and economic challenges without ethical concerns or legal barriers.
Navigating Regulations with Ease
Since synthetic data doesn’t include personal details, it’s exempt from many data protection laws. For instance, synthetic health data isn’t covered by HIPAA, and synthetic student data isn’t restricted by FERPA, making it a much easier alternative for researchers to navigate complex legal requirements.
2. Improved Accuracy and Research Confidence
Synthetic data enhances the accuracy and reliability of research. Unlike traditional methods that may rely on limited samples, synthetic data generates comprehensive, statistically representative datasets that mirror real-world demographics and behaviors. This ensures that the insights researchers derive are trustworthy and actionable.
Testing Policy Scenarios
With synthetic data, researchers can simulate the effects of different policies across various demographic groups, testing multiple scenarios before they are implemented. This is especially useful for controversial or sensitive topics like immigration reform or criminal justice changes, allowing researchers to explore outcomes without directly involving real individuals.
Maintaining Data Quality
Synthetic data maintains the integrity of the original dataset while ensuring accurate outcomes. The data is validated against known benchmarks like census data or demographic trends, ensuring the results align with real-world patterns. This consistency enables researchers to avoid the common pitfalls of traditional data collection, such as biases or seasonal shifts.
3. Faster Research Timelines and Lower Costs
Synthetic data significantly reduces both the time and cost required to conduct research. Traditional public policy studies often take months and cost hundreds of thousands of dollars. Synthetic data, on the other hand, can provide insights in just 30-60 minutes and slash research costs by as much as 90%.
Lightning-Fast Insights
Synthetic data enables real-time insights, allowing researchers to quickly test and refine policy proposals without long delays. This rapid feedback cycle ensures that policymakers can adjust their strategies in real-time, making decisions faster and with greater confidence.
Budget-Friendly Research
By cutting research costs, synthetic data enables more extensive studies without breaking the budget. Subscription-based pricing models provide predictable costs, making it easier for researchers to fund ongoing projects without unforeseen expenses.
4. Greater Flexibility and Research Access
Synthetic data enables researchers to access diverse demographics instantly and make real-time adjustments to their studies. This flexibility allows researchers to explore scenarios and populations that would be difficult or expensive to reach with traditional methods.
Access to Any Audience
With synthetic data, researchers can generate datasets for specific groups or populations, such as healthcare workers, small business owners, or federal employees, without the need for lengthy recruitment processes.
Real-Time Adjustments
Unlike traditional methods, where research parameters are set in stone once the study begins, synthetic data allows researchers to adjust datasets on the fly. Whether tweaking demographics or exploring new response patterns, synthetic data’s adaptability ensures studies remain relevant and responsive to changing circumstances.
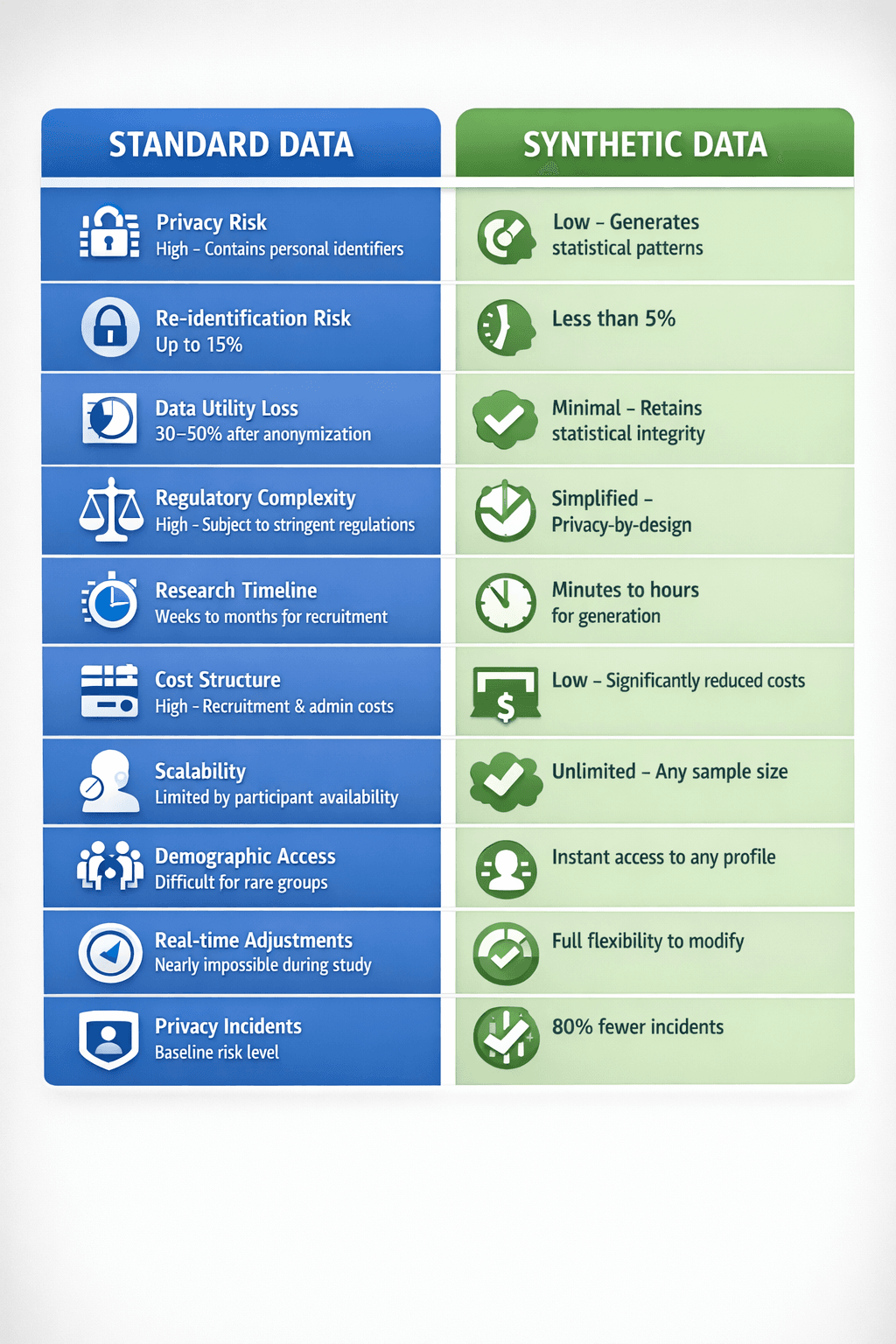
Comparison: Standard Data vs. Synthetic Data in Public Policy Research
The differences between standard and synthetic data are clear when it comes to privacy, accuracy, efficiency, and adaptability. Below is a comparison table highlighting these distinctions:
| Aspect | Standard Data | Synthetic Data |
|---|---|---|
| Privacy Risk | High – Contains personal identifiers | Low – Generates statistical patterns |
| Re-identification Risk | Up to 15% | Less than 5% |
| Data Utility Loss | 30–50% after anonymization | Minimal – Retains statistical integrity |
| Regulatory Complexity | High – Subject to stringent regulations | Simplified – Adheres to privacy-by-design |
| Research Timeline | Weeks to months for participant recruitment | Minutes to hours for data generation |
| Cost Structure | High – Recruitment, incentives, administration | Low – Significantly reduced costs |
| Scalability | Limited by participant availability | Unlimited – Can produce any sample size |
| Demographic Access | Difficult for rare or hard-to-reach groups | Instant access to any demographic profile |
| Real-time Adjustments | Nearly impossible once study begins | Full flexibility to modify parameters |
| Privacy Incidents | Baseline risk level | 80% fewer incidents reported |
Conclusion: Transforming Public Policy Research with Synthetic Data
Synthetic data is revolutionizing public policy research by offering unparalleled benefits in terms of privacy, accuracy, speed, and flexibility. It helps researchers navigate complex regulatory environments while delivering reliable, cost-effective insights in record time. With platforms like Syntellia at the forefront, synthetic data is becoming an essential tool for modern policymaking.
Frequently Asked Questions (FAQs)
1. How does synthetic data protect privacy while delivering accurate insights for public policy research?
Synthetic data uses statistical models to generate artificial datasets that mimic real-world patterns without revealing any personal details, ensuring privacy while maintaining accuracy.
2. How does synthetic data make public policy research faster and more cost-effective than traditional methods?
Synthetic data cuts down on recruitment time and operational costs, offering researchers insights in minutes at a fraction of the price of traditional methods.
3. What are some examples of how synthetic data benefits public policy research?
Synthetic data enables simulations for healthcare policies, economic planning, and transportation models, providing valuable insights for better decision-making.